大数据培训 Hadoop与MPP的区别及其在信息系统集成服务中的应用
在大数据时代,越来越多的企业和组织开始投资大数据技术来优化业务决策和提升效率。作为大数据领域的两个核心技术,Hadoop和MPP(Massively Parallel Processing,大规模并行处理)系统在信息系统集成服务中扮演着不同的角色。理解它们之间的区别对于选择合适的技术方案至关重要。
一、Hadoop与MPP的基本概念
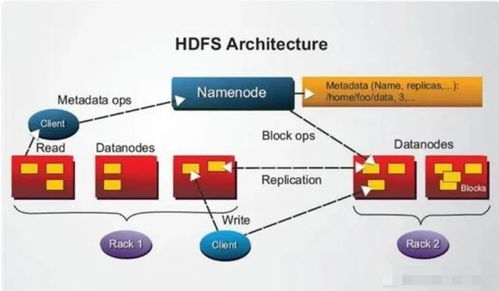
Hadoop 是一个开源的分布式计算框架,主要用于处理海量非结构化数据的存储和处理。其核心组件包括HDFS(分布式文件系统)和MapReduce(并行处理模型)。Hadoop适用于批处理任务,能够处理PB级别的数据,但通常延迟较高,适合非实时分析场景。
MPP(大规模并行处理) 是一种数据库架构,通过将数据分布在多个节点上并行处理查询,从而实现高性能的数据分析。典型的MPP系统包括Greenplum、Teradata等。MPP适用于复杂查询和实时分析,延迟较低,适合需要快速响应的业务场景。
二、Hadoop与MPP的主要区别
- 数据处理模式:
- Hadoop采用批处理模式,适合处理大批量数据,但响应时间较长。
- MPP采用交互式查询模式,支持低延迟的实时分析。
- 数据存储结构:
- Hadoop支持非结构化和半结构化数据(如日志、文本),灵活性强。
- MPP主要针对结构化数据,优化了SQL查询性能。
- 扩展性与成本:
- Hadoop基于廉价硬件构建,横向扩展成本较低,适合大规模数据存储和计算。
- MPP系统通常依赖专用硬件,扩展成本较高,但性能更稳定。
- 应用场景:
- Hadoop常用于数据仓库的ETL过程、历史数据分析和大规模数据挖掘。
- MPP更适用于实时报表、OLAP(在线分析处理)和高并发查询。
三、在信息系统集成服务中的应用
在信息系统集成服务中,Hadoop和MPP可以根据业务需求进行组合使用。例如,企业可以利用Hadoop进行原始数据的采集和预处理,然后将处理后的结构化数据导入MPP系统进行快速分析和报表生成。这种混合架构能够兼顾成本效益和性能需求。
大数据培训应强调Hadoop和MPP的实际操作和集成方法,帮助学员掌握如何根据业务场景选择合适的技术方案,并实现高效的信息系统集成服务。
四、总结
Hadoop和MPP各有优势,Hadoop适合处理海量非结构化数据,而MPP则在结构化数据的实时分析方面表现出色。在大数据培训和信息系统集成服务中,理解它们的区别并灵活应用,将有助于构建高效、可扩展的数据处理平台。
如若转载,请注明出处:http://www.sol2017.com/product/21.html
更新时间:2025-11-29 07:24:33